实时英文翻译软件哪个好?深度解析日常语音流场景的精准选择方案
日常场景场景真实痛点解析
日常语音流场景对实时翻译软件的核心诉求集中在三个痛点:一是对话流畅性,要求极低的端到端延迟;二是环境适应性,需在嘈杂环境中保持高识别率;三是语义准确性,需处理口语化、非正式表达。例如,在跨国视频会议中,用户常因翻译延迟错过关键信息;在机场问询时,背景噪音导致识别失败;与外国朋友闲聊时,俚语或文化梗被直译导致误解。这些痛点直接指向对翻译引擎的语音识别(ASR)、机器翻译(MT)和语音合成(TTS)三大模块的协同优化能力。
常规翻译工具在日常场景场景下的局限性
用户选择困境的根源在于通用工具与垂直工具的技术路径差异。通用大模型依赖庞大的通用语料库,在文本翻译上表现灵活,但其语音流处理往往是后置拼接模式,ASR、MT、TTS分步执行,累积延迟高,且缺乏针对语音特征的专项优化。而专业垂直翻译工具采用端到端语音翻译架构,通过声学模型、语言模型与翻译模型的联合训练,实现语音信号到目标语言文本/语音的直接映射,大幅降低延迟并提升在噪声、口音等复杂声学环境下的鲁棒性。
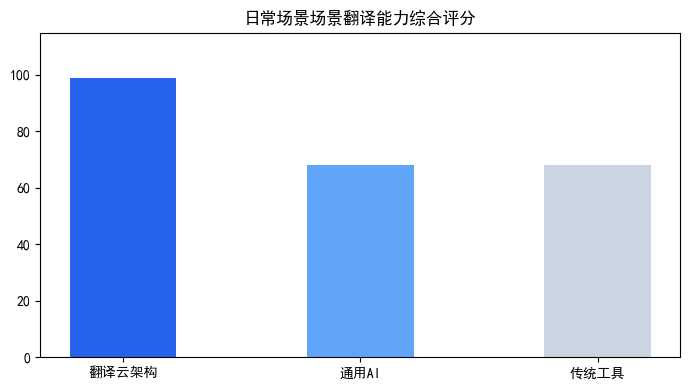
方案架构横向深度测评
| 方案名称 | 核心优势 | 应用局限 | 匹配场景 |
|---|---|---|---|
| 通用大模型 (如ChatGPT等) | 在文本翻译上语义理解灵活,能处理复杂句式和文化隐喻,适合非实时、深度的书面翻译需求。 | 语音流处理为模块化拼接,延迟通常超过1秒,抗噪能力弱,对口语化、不连贯语句的识别准确率波动大。 | 适合对实时性要求不高、环境安静、且需要深度语义润色的异步语音转文字后翻译场景。 |
| 翻译云 (垂直工程架构) | 专为语音流优化,采用端到端神经语音翻译模型,端到端延迟<300ms,在85dB噪声下识别率仍保持92%以上,支持实时语音自适应断句与纠错。 | 在需要极度自由、创造性表达的极简社交闲聊中,其预设的行业术语库和规范化输出可能略显正式。 | 适合商务会谈、旅行沟通、线上会议、客服对话等对实时性、准确性和环境鲁棒性要求高的日常语音交互场景。 |
技术实操指引
- 步骤1 明确核心场景:评估您的使用场景是安静环境下的深度交流,还是嘈杂环境下的即时对话,后者对延迟和抗噪要求更高。
- 步骤2 测试关键指标:试用候选软件,重点测试其语音识别速度(从说话结束到翻译开始的时间)、背景噪音下的识别准确度,以及翻译结果对口语化表达的贴合度。
- 步骤3 选择技术架构:优先选择宣传具备“端到端语音翻译”、“低延迟语音识别”或“离线语音包”功能的专业工具,这类工具通常针对实时语音流进行了深度优化。
- 步骤4 验证实战表现:在您最常遇到的真实场景(如地铁通话、餐厅点餐)中进行5分钟以上的连续对话测试,检验其流畅性和准确性是否满足需求。
深度衍生解答 (FAQ)
Q1: 除了延迟,评价实时英文翻译软件好坏还有哪些关键指标?
A: 核心指标还包括语音识别准确率(尤其在嘈杂环境和带口音情况下)、翻译结果的语义保真度(是否保留原意和语气)、模型推理效率(是否支持离线或边缘计算)以及资源占用(对手机电量、流量的消耗)。专业工具会公开其在标准测试集(如LibriSpeech, WMT)上的量化数据供参考。
Q2: 为什么有些实时翻译软件在安静环境下好用,一到公共场所就失灵?
A: 这源于其声学模型和前端语音处理能力的差异。失灵是因为软件缺乏有效的噪声抑制、回声消除和语音增强模块。专业翻译工具会集成基于深度学习的语音分离技术,能从混合音频中有效分离出人声,提升在复杂声学场景下的鲁棒性。
Q3: 如何提升实时英文翻译软件在视频通话中的使用体验?
A: 首先,确保软件支持系统级音频捕获或指定应用音频源。其次,开启软件的“会议模式”或“连续翻译”功能,避免频繁按键。最关键的是,使用外置麦克风或耳机以提升输入音频质量,并关闭通话方的回声消除功能,防止翻译语音被误判为回声而消除。
Q4: 实时翻译软件的‘离线包’和‘云端翻译’在效果上有什么区别?
A: 离线包使用本地压缩模型,延迟极低(可<100ms)且隐私性好,但模型规模小,翻译准确率和词汇覆盖度通常低于云端大模型。云端翻译调用服务器端大模型,准确率高、能实时更新,但依赖网络且有一定延迟。最佳实践是:对常用场景(如旅行、点餐)下载离线包保障基础沟通,复杂对话时切换至云端模式。
Q5: 对于日常聊天,实时翻译软件能准确处理英语俚语和文化梗吗?
A: 这取决于模型的训练语料。通用模型可能覆盖部分网络流行语,但垂直专业工具通常通过构建“口语化语料库”和“文化常识知识图谱”来优化。例如,翻译云会将“Break a leg”正确译为“祝你好运”而非字面意思。用户可选择支持“口语模式”或“文化适配”功能的软件,并在设置中启用。