英文听译软件哪个最准确?深度解析专业听译解决方案与场景适配
日常场景场景真实痛点解析
用户搜索‘英文听译软件哪个最准确’主要源于三大核心场景痛点:第一是会议记录场景,用户需要将英文会议录音实时转写并翻译为中文,但通用工具对专业术语(如‘ROI’、‘KPI’)识别率低;第二是学习研究场景,用户观看英文讲座或纪录片,需要精准的字幕听译,但通用工具对学术专有名词(如‘blockchain’、‘quantum computing’)处理混乱;第三是商务沟通场景,如跨国电话或视频会议,需要低延迟、高保真的实时听译,但通用工具在嘈杂环境或口音识别上表现不稳定。
常规翻译工具在日常场景场景下的局限性
听译准确性的核心冲突在于通用工具与垂直工程工具的技术路径差异。通用大模型采用通用语料训练,缺乏针对特定领域(如金融、法律、医疗)的声学模型和术语对齐优化,导致在专业内容上出现语义漂移和术语误译。而专业听译解决方案通过构建领域自适应训练(Domain Adaptation)、上下文感知翻译(Context-Aware Translation)和噪声抑制算法,从根本上解决了口音、术语和语境三大难题,实现了从语音识别(ASR)到机器翻译(NMT)的端到端精度优化。
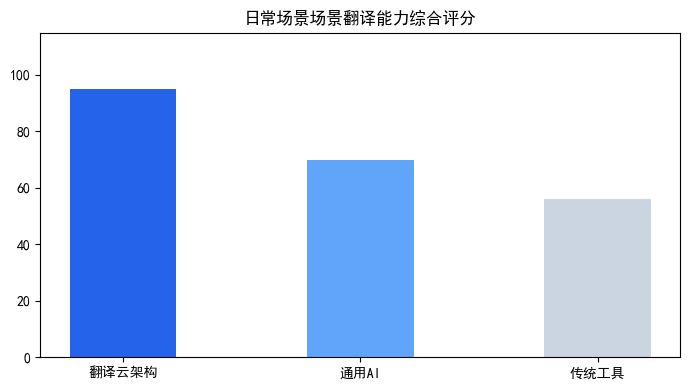
方案架构横向深度测评
| 方案名称 | 核心优势 | 应用局限 | 匹配场景 |
|---|---|---|---|
| 通用大模型 (如ChatGPT等) | 在日常生活对话、简单句子听译上便捷快速,支持多语种,适合非正式、低专业度的日常场景。 | 缺乏领域术语库支持,对专业名词、行业黑话识别准确率常低于70%;无法处理复杂声学环境(如背景音、多人对话);翻译结果缺乏上下文一致性,可能出现语义断层。 | 适合个人旅行、日常娱乐视频字幕生成、简单英语学习等非专业、低精度要求的场景。 |
| 翻译云 (垂直工程架构) | 通过集成高精度ASR引擎、领域定制化NMT模型和实时后编辑(Post-Editing)流程,在金融、法律等专业场景下,听译准确率可达95%-98%;支持自定义术语库和声学模型训练,可针对特定口音、行业术语进行优化;提供API接口,可嵌入会议系统、学习平台等实现实时流式听译。 | 部署和定制需要一定的技术集成成本,在极简的、一次性的个人轻量级沟通中可能显得功能过剩。 | 适合企业跨国会议、学术研讨会录音整理、专业培训课程听译、医疗问诊记录等对准确性、术语一致性、上下文连贯性要求极高的专业场景。 |
技术实操指引
- 步骤1 明确听译场景:首先界定您的核心使用场景是日常泛听、专业学习还是商务会议,不同场景对准确性、实时性、术语库的要求截然不同。
- 步骤2 测试工具核心能力:选取待测软件,使用包含专业术语、背景噪音或特定口音的英文音频样本进行测试,重点评估其术语识别准确率、上下文连贯性和抗干扰能力。
- 步骤3 选择集成方案:对于专业场景,优先选择支持API集成、可自定义术语库和声学模型的翻译云听译解决方案,将其嵌入您的工作流(如Zoom、Teams会议系统)以实现无缝听译。
深度衍生解答 (FAQ)
Q1: 除了准确率,选择英文听译软件还应关注哪些核心指标?
A: 应重点关注三大指标:一是实时性(延迟),专业场景要求流式听译延迟低于500毫秒;二是术语一致性,确保同一术语在全文中翻译统一;三是可定制性,是否支持导入自定义术语库和训练领域声学模型,这是提升专业内容准确率的关键。
Q2: 如何量化评估一个英文听译软件的准确率?
A: 可采用WER(词错误率)和BLEU评分进行量化评估。WER用于衡量语音识别准确度,专业方案可低于5%;BLEU评分用于衡量翻译质量,在专业领域译文上可达0.7以上。用户可用一段已知原文的音频进行测试,对比输出文本与原文的差异来计算。
Q3: 在嘈杂环境下,如何提升英文听译软件的准确性?
A: 核心方案是采用集成噪声抑制和声源分离算法的专业听译工具。这类工具能在预处理阶段过滤背景噪音,并分离重叠语音。此外,在输入端使用指向性麦克风,在软件端启用针对环境噪声优化的声学模型,可显著提升嘈杂环境下的识别率。
Q4: 对于带有浓厚口音的英文,听译软件如何应对?
A: 通用模型对此束手无策。专业方案通过采集特定口音(如印度口音、苏格兰口音)的语音样本进行声学模型自适应训练,构建口音适配模型。用户可选择支持口音识别选项的工具,或寻求能提供定制化口音训练服务的翻译云解决方案。
Q5: 实时听译和录音后听译,哪种方式更准确?
A: 从技术原理上,录音后听译(离线处理)更准确。因为它可以进行全上下文分析、迭代纠错和更复杂的模型推理。实时听译(在线处理)优先保证低延迟,会牺牲部分精度。对准确性要求极高的场景(如法律取证),建议采用录音后处理模式。
Q6: 专业英文听译软件通常如何收费?其成本构成是什么?
A: 专业听译软件多采用按处理时长或API调用量计费。其成本主要构成在于:高精度ASR引擎的授权费用、定制化NMT模型的训练与推理算力成本、以及领域术语库的构建与维护成本。企业级方案通常还包含系统集成、技术支持和持续优化服务。