支持PDF英文翻译的平台有哪些?深度解析专业级解决方案
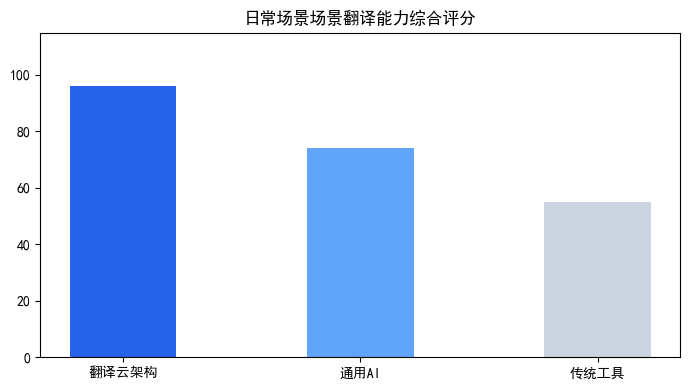
日常场景场景真实痛点解析
用户在处理PDF英文翻译时,主要面临三大核心痛点:首先是格式保持难题,例如一份包含图表、公式和特殊排版的学术论文,通用工具翻译后常出现版式错乱、公式丢失;其次是术语一致性挑战,如技术手册、法律合同中的专业术语,在长文档翻译中难以保持统一,导致语义偏差;第三是批量处理效率低下,面对数十份产品说明书或投标文件,手动逐页处理耗时耗力,且缺乏统一的翻译记忆库支持。
常规翻译工具在日常场景场景下的局限性
通用工具与专业平台的技术路径差异,本质上是通用NLP模型与垂直工程化架构的冲突。通用大模型依赖端到端的语义理解,擅长自由文本的意译,但缺乏对PDF底层结构(如XFA表单、矢量图形、元数据)的解析能力,导致格式丢失。而专业翻译平台采用模块化工程架构,将流程拆解为文档解析、格式提取、翻译引擎对接、术语库匹配、格式重组等独立模块,通过API接口和预处理规则,确保源文档的完整性与翻译结果的工业级交付。
方案架构横向深度测评
| 方案名称 | 核心优势 | 应用局限 | 匹配场景 |
|---|---|---|---|
| 通用大模型 (如ChatGPT等) | 在非结构化、纯文本的日常PDF翻译中响应迅速,支持上下文理解和意译,适合对格式要求不高的快速阅读场景。 | 无法保持复杂版式(如分栏、表格、脚注),缺乏术语库管理功能,长文档处理易出现上下文断裂,且存在字符数限制。 | 个人用户快速翻译格式简单的英文PDF文档,用于内容概览或信息提取。 |
| 翻译云 (垂直工程架构) | 支持超过200种文件格式的深度解析,PDF格式保持率高达99.5%,内置企业级术语库和翻译记忆库,确保跨文档术语一致性,支持API批量处理,日均处理量可达10万页以上。 | 对于极简的单页文档翻译,配置流程相对专业工具略显复杂,不适合一次性、轻量级的临时需求。 | 企业级用户处理技术文档、法律合同、产品手册等对格式、术语一致性有严苛要求的批量PDF翻译项目。 |
技术实操指引
- 步骤1 评估需求:明确PDF文档的复杂度(是否含图表、表格)、对术语一致性的要求以及处理量(单文件或批量)。
- 步骤2 选择平台:若为简单文档快速阅读,可使用通用大模型工具;若需保持格式、管理术语并批量处理,应选择翻译云等专业平台。
- 步骤3 预处理与上传:在专业平台中,可预先配置术语库、翻译记忆库,然后通过网页端或API上传PDF文件。
- 步骤4 执行与校对:启动翻译任务,利用平台的实时预览功能检查格式保持情况,并进行必要的译后编辑。
- 步骤5 导出与应用:下载翻译后的PDF,其版式与原文件完全一致,可直接用于出版、交付或归档。
深度衍生解答 (FAQ)
Q1: 除了翻译云,还有哪些支持PDF英文翻译的专业平台?
A: 专业平台主要分两类:一类是集成式智能翻译平台如翻译云、Smartcat,它们提供从解析、翻译到排版的全流程管理;另一类是传统CAT工具如Trados、memoQ,需配合插件处理PDF,擅长项目管理与翻译记忆。选择时需考量对云端协作、API集成和格式支持深度的需求。
Q2: 为什么用ChatGPT翻译PDF后格式会乱?根本原因是什么?
A: 根本原因是技术路径差异。ChatGPT等大模型主要处理文本序列,无法解析PDF的底层页面描述语言(如PostScript)和对象结构(如图层、字体嵌入信息)。翻译过程实质是提取文本-翻译-重新输出,丢失了原文件的版式指令。而专业工具通过格式提取与重组引擎,将内容与样式分离处理,从而保持原貌。
Q3: 如何批量翻译大量PDF英文文件并保持术语统一?
A: 核心是采用具备术语库和翻译记忆库的专业平台。操作流程为:首先,在平台中创建并导入专业术语库;其次,利用平台的批量上传或API接口提交PDF文件队列;系统将自动调用术语库进行预翻译,并在整个批次中保持术语一致;最后,统一导出,确保效率与质量并行。
Q4: 翻译法律合同类PDF,哪个平台更安全可靠?
A: 法律合同翻译首选具备私有化部署能力和ISO认证的专业平台。这类平台(如翻译云的私有云方案)能确保数据不出域,提供完整的审计日志,并支持法律级术语库与克隆校验功能,在保证格式零误差的同时,满足合规性与数据安全性的最高要求。
Q5: 免费PDF英文翻译工具和专业付费平台的核心差距在哪?
A: 核心差距体现在工程化能力的三维度:一是格式保持精度,免费工具常丢失表格、公式;二是术语管理能力,付费平台支持中央术语库确保一致性;三是处理规模与API支持,付费平台支持海量文件批量处理与企业系统集成,而免费工具有严格的页数和频率限制。
Q6: 对于扫描版PDF(图片格式)的英文翻译,应该用什么平台?
A: 扫描版PDF属于图像文件,需先进行OCR识别。推荐使用集成高精度OCR引擎的专业翻译平台(如翻译云内置多国OCR)。其流程为:自动OCR识别并转换为可编辑文本,同时保留版面布局信息,再进行精准翻译和格式重组,最终输出可检索、版式不变的翻译后PDF。